// 迭代 voidbubbleSort(vector<int>& nums){ for (int i = nums.size() - 1; i > 0; --i) { for (int j = 0; j < i; ++j) { if (nums[j] > nums[j + 1]) { swap(nums[j], nums[j + 1]); } } } }
// 递归 voidbubble(vector<int>& nums, int l, int r){ if (l >= r) return; for (int k = l; k < r; ++k) { if (nums[k] > nums[k + 1]) swap(nums[k], nums[k + 1]); } bubble(nums, l, r - 1); }
voidinsertion_sort(int nums[], int n){ for (int i = 1; i < n; ++i) { int cur = nums[i]; int j = i - 1; while (j >= 0 && cur < nums[j]) { nums[j + 1] = nums[j]; --j; } nums[j + 1] = cur; } }
Bottom-up
Bottom-up的方式主要依赖于一种叫做heapify的操作,你也可以叫它嬉皮化。对某个结点a进行heapify非常简单:对比a以及a两个孩子\(c_1,c_2\)的值,如果a是最大的,操作结束;否则将a与\(max(c_1,c_2)\)交换,递归直到a变为叶子结点或者a是三者中最大值,heapify操作的复杂度为\(O(lgn)\)。
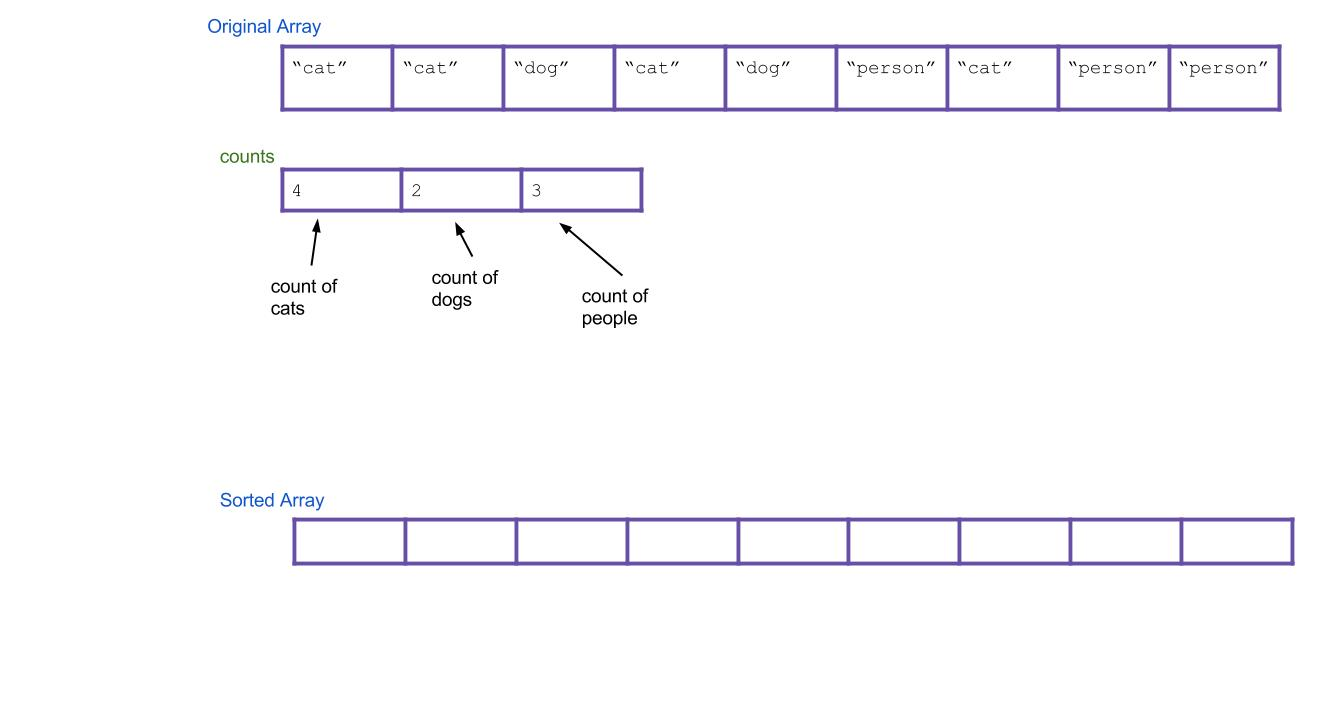
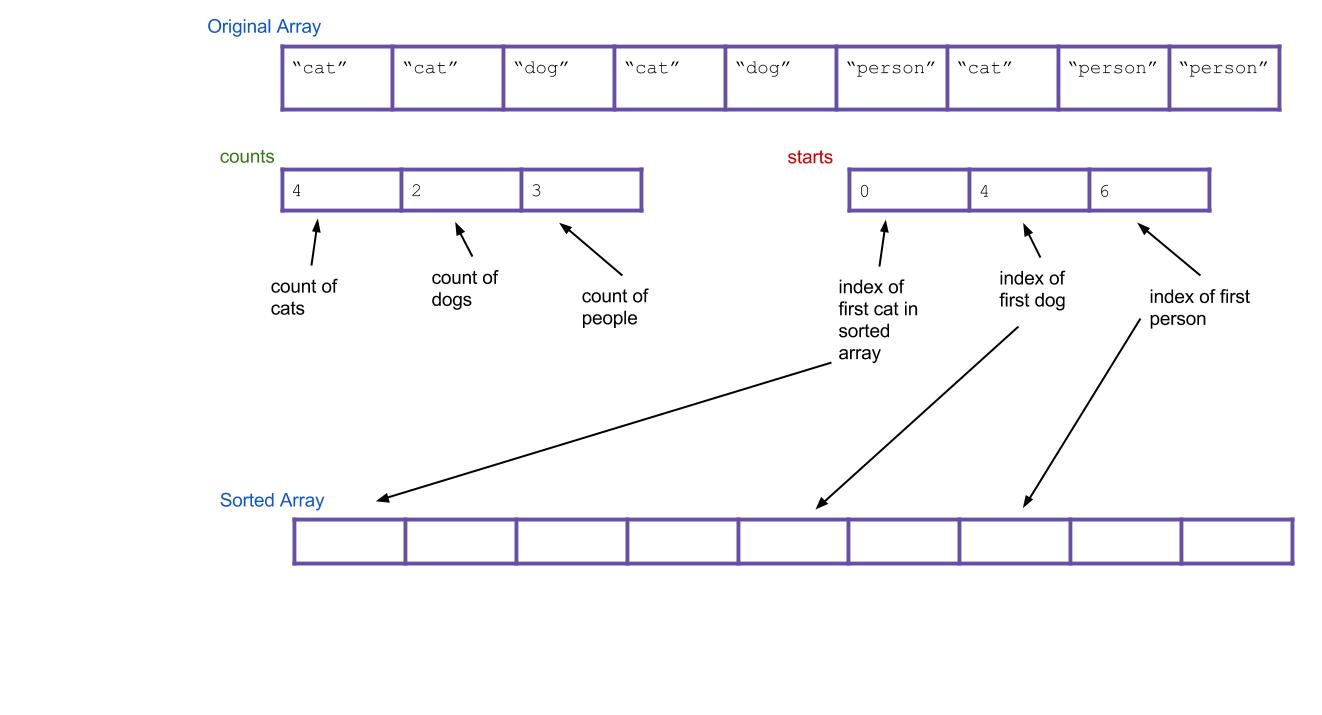
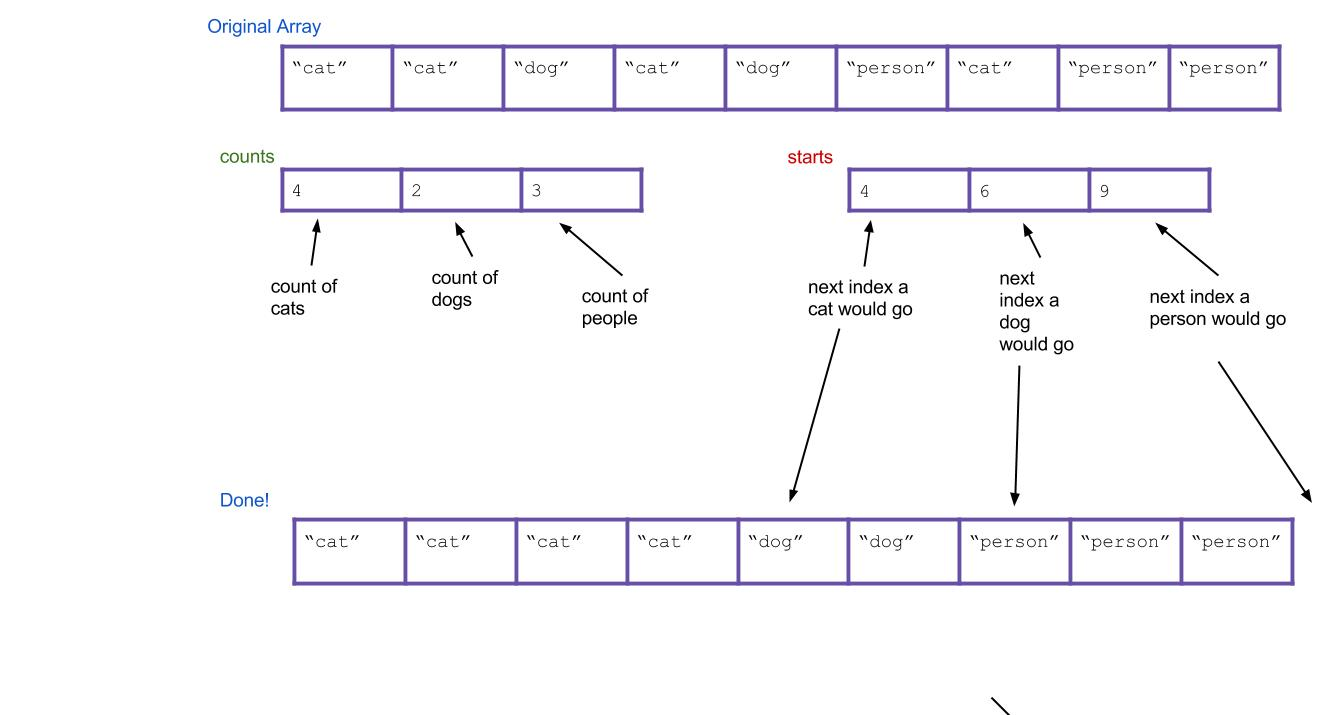
可以发现:一次heapify下沉操作sift_down只能保证从a向下交换的路径上的每一棵局部小子树满足堆的性质(即只对原数组的部分位置进行了调整),并不能保证整棵树都满足堆的性质,甚至无法保证向下交换的整条路径满足根结点最大(如[3 2 4 0 1 6 8]对根操作后变为[4 2 8 0 1 6 3]),所以为了建堆,需要从最后一个非叶子结点\((n-1-1)//2\)(也即最后一个结点的父结点)开始,对之前的每个结点都进行heapify操作,这样就可以保证整棵树都满足堆的性质。时间复杂度为\(O(n)\),How
can building a heap be O(n) time complexity?
那么heapify建堆能不能从前向后进行呢?答案是不能,还是上面那个例子。从前往后最大元素调不到堆顶,从后往前则已经保证了父结点是最大的,因此最大元素可以一直向上调。
// Inserted num is now at idx and sift up voidheap_insert(vector<int>& nums, int idx){ while (nums[idx] > nums[(idx - 1) / 2]) { swap(nums[idx], nums[(idx - 1) / 2]); idx = (idx - 1) / 2; } }
// 在[start, end]范围内对nums[start]向下调整 voidheapify(vector<int>& nums, int start, int end){ if (start >= end) return; int maxIdx = start, left = 2 * start + 1, right = 2 * start + 2; if (left <= end && nums[left] > nums[maxIdx]) maxIdx = left; if (right <= end && nums[right] > nums[maxIdx]) maxIdx = right; if (maxIdx != start) { swap(nums[start], nums[maxIdx]); heapify(nums, maxIdx, end); } }
voidheapifyIter(vector<int>& nums, int start, int end){ while (2 * start + 1 <= end) { int maxIdx = start, left = 2 * start + 1, right = 2 * start + 2; if (left <= end && nums[left] > nums[maxIdx]) maxIdx = left; if (right <= end && nums[right] > nums[maxIdx]) maxIdx = right; if (maxIdx == start) { // 父亲最大无法继续下沉 break; } swap(nums[start], nums[maxIdx]); start = maxIdx; } }
voidbuildMaxHeap(vector<int>& nums){ int lastIdx = nums.size() - 1; for (int i = (lastIdx - 1) / 2; i >= 0; --i) { heapify(nums, i, lastIdx); } }
voidheapSort(vector<int>& nums){ buildMaxHeap(nums); for (int i = nums.size() - 1; i > 0; --i) { swap(nums[0], nums[i]); heapify(nums, 0, i - 1); } }
/** * partition nums into two regions: <= > * * [l, small_idx]: <= pivot * [small_idx + 1, i - 1]: > pivot * [i, r): unvisited */ intpartition(vector<int>& nums, int l, int r){ srand(time(nullptr)); int index = l + rand() % (r - l + 1); swap(nums[index], nums[r]); // now the pivot is nums[r] int smallerIndex = l - 1; for (int i = l; i < r; ++i) { if (nums[i] <= nums[r]) { // nums[i] < nums[r]也可 swap(nums[i], nums[++smallerIndex]); } } swap(nums[r], nums[++smallerIndex]); return smallerIndex; }
/** * partition num into 3 regions: < == > (荷兰国旗问题) * @return lowerbound and upperbound of pivot inclusive * * [l, small_idx]: < pivot * [small_idx + 1, i - 1]: == pivot * [i, big_idx - 1]: unvisted * [big_idx, r): > pivot */ pair<int, int> partition(vector<int>& nums, int l, int r){ srand(time(nullptr)); int index = l + rand() % (r - l + 1); swap(nums[index], nums[r]); // now the pivot is nums[r] int smallerIndex = l - 1, greaterIndex = r; int i = l; while (i < greaterIndex) { if (nums[i] < nums[r]) { swap(nums[i++], nums[++smallerIndex]); } elseif (nums[i] == nums[r]) { i++; } else { swap(nums[i], nums[--greaterIndex]); } } swap(nums[r], nums[greaterIndex]); return {++smallerIndex, greaterIndex}; }
voidquickSort(vector<int>& nums, int l, int r){ if (l >= r) { return; } int pivotIndex = partition(nums, l, r); quickSort(nums, l, pivotIndex - 1); quickSort(nums, pivotIndex + 1, r); }
// 非递归,用栈保存要操作的范围的下标 voidquickSortIter(vector<int>& num, int low, int high){ stack<int> s; s.push(low); s.push(high);
while (!s.empty()) { int r = s.top(); s.pop(); int l = s.top(); s.pop(); int pivotPos = partition(num, l, r); if (l < pivotPos - 1) { s.push(l); s.push(pivotPos - 1); } if (pivotPos + 1 < r) { s.push(pivotPos + 1); s.push(r); } } }
intpartition(vector<int>& num, int low, int high){ int pivot = num[low]; while (low < high) { while (low < high && num[high] >= pivot) { --high; } num[low] = num[high]; while (low < high && num[low] <= pivot) { ++low; } num[high] = num[low]; } num[low] = pivot; return low; }
voidradixsort(vector<int>& num, int l, int r, int max_digit_cnt){ int radix = 1; vector<int> tmp(r - l + 1); for (int d = 0; d < max_digit_cnt; ++d) { vector<int> cnt(10, 0); for (int i = l; i <= r; ++i) { int digit = num[i] / radix % 10; ++cnt[digit]; } for (int i = 1; i < 10; ++i) { cnt[i] += cnt[i - 1]; } for (int i = r; i >= l; --i) { int digit = num[i] / radix % 10; tmp[--cnt[digit]] = num[i]; } for (int i = l; i <= r; ++i) { num[i] = tmp[i]; } radix *= 10; } }
Bucket Sort
1 2 3 4 5 6 7 8 9 10 11 12 13 14
voidbucketSort(vector<int>& nums, int upper){ int len = nums.size(); vector<vector<int>> buckets(len); for (int num : nums) { buckets[num * len / upper].emplace_back(num); } int idx = 0; for (auto bucket : buckets) { std::sort(bucket.begin(), bucket.end()); for (int num : bucket) { nums[idx++] = num; } } }