Decision Tree
Details
决策树的发展经历了CART(Classification and Regression Tree), ID3,
C4.5等多个阶段:
CART是一种二叉树,分类树采用基尼系数,回归树采用平方误差。
ID3主要用于分类,是一种多叉树结构,采用信息增益。
C4.5主要用于分类,是一种多叉树结构,采用信息增益比。
最终的模型为: \[f(x)=\sum_{i=1}^{m}C_iI(x\in
R_i),I(x\in R_i)=\begin{cases}
1, & \text{x$\in$ $R_i$} \\
0, & \text{else}
\end{cases}\] m表示数据集被划分的子集数目,\(C_i\)表示第i个单元的输出值 ## Example ##
Implementation ## Properties
Motivation
Random Forest is some kind of ensemble learning method, just as its name indicates. The base learner is decision tree and RF uses Bagging to integrate. The difference mainly lies in the word 'Random'. The original decision tree selects the best attribute while RF has two steps to select a split attribute for each base learner:
- Select k attributes from \(A\) randomly;
- Select the best attribute from the k attributes. If k=1 then it's total random selection; If k=\(|A|\) then it's the same as decision tree. The recommended is \(k=log_2|A|\).
The intuition behind this is to increase the diversity of the base learners. In original bagging method we just use the sample disturbance of the training data. But in RF we add the attribute disturbance thus making the learner generalize very well.
As you can imagine, RF's performance is worse than Bagging during the early time of the training process. Since we just use a subset of the attributes so the base learner performs not that well. But with the increase of the number of base learners, it will gradually use the whole information and then has a low generation error. By the way, RF is often faster than Bagging since we only use a subset to train the base learners.
随机森林回归
决策树回归的叶子结点代表一小片区域,落入该区域的训练样例的均值被用来作为该区域的预测值:
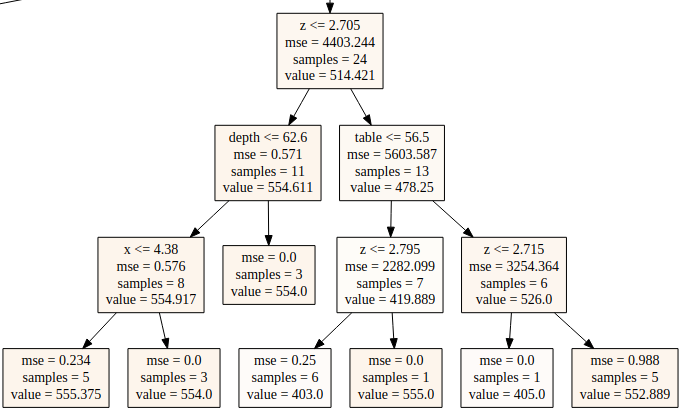
例如上图中右下角的叶子结点的值552.899就是落入该区域的5个样本的均值。
随机森林则是由若干棵决策树通过某些“随机”的方式构建而成,包括样本随机和属性随机,最终的预测结果由所有树的平均得到。
但是它不像线性回归那样在预测时可以外推,如果仔细观察最终参与决策的树的某一部分:
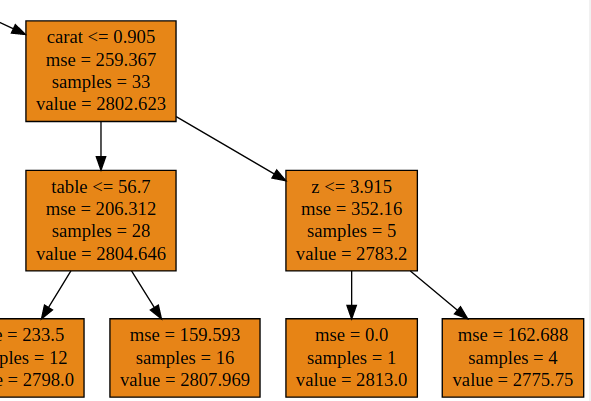
可以看到:在carat<0.905和z<3.915这个区域共有4个训练样本,因此测试集中任意一个落入此区域的样本都会被预测为4个样本的均值2775.75,自然也就不会超过这4个样本的取值极限。
如果要预测某个target
value超出训练集极限的样例,其预测结果仍然是训练集中某些样本的均值。
缺失值处理:我在科研中见到的都是先用常数填充训练数据和测试数据,再去扔给模型训练和预测。
我使用sklearn中标准的RandomForestRegressor进行了尝试,如果训练数据包含缺失值,那么训练将会报错。
## Example ## Implementation ## Properties ## Refs Random
Forest Regression: When Does It Fail and Why?

