链表一直是面试的重点问题,恰好最近看到了Stanford的一篇材料,涵盖了链表的基础知识以及派生的各种问题。
第一篇主要是关于链表的基础知识。
基本结构
1、数组回顾
链表和数组都是用来存储一堆数据的集合,其中单个元素的类型可以有很多种。
通过数组下标可以直接访问数组中的元素,比如:
1 | void ArrayTest() |
最关键的是:整个数组被分配了一整块内存:

数组元素之所以能被快速访问,原因在于其地址的计算是通过首地址加上偏移值得到的,只有一次乘法和一次加法运算而已。
数组的缺点在于:
- 数组的大小是固定的:数组的规模在编译时就被确定,当然你可以在运行时通过
malloc在堆中改变数组的大小,不过很麻烦; - 由于上述原因,所以很多人就会定义一个很大的数组,不过这又会导致两个问题:
1)数组的大部分空间可能被浪费掉;
2)如果程序需要更大的空间,就会崩溃。 - 在数组前面插入元素代价很大,需要移动很多元素。
链表也有自己的优缺点,只不过和数组刚好互补:链表会在需要时为每个节点单独分配内存。
2、指针回顾
指针存储了变量的地址,如果指针的值是NULL(c/c++中NULL可以表示逻辑false),那么该指针不指向任何变量。
在c/c++中,没有初始化的指针就是野指针,对野指针进行dereference操作可能导致程序崩溃。
两个指针的赋值结果就是都指向相同的内存区域。
malloc()函数用来在堆中申请一块内存,并且返回一个指向该块的指针,如果申请失败,会返回NULL,使用后,需要用free()去释放。这些堆函数原型都在stdlib.h头文件中声明。
3、链表
一个包含{1,2,3}三个元素的链表:
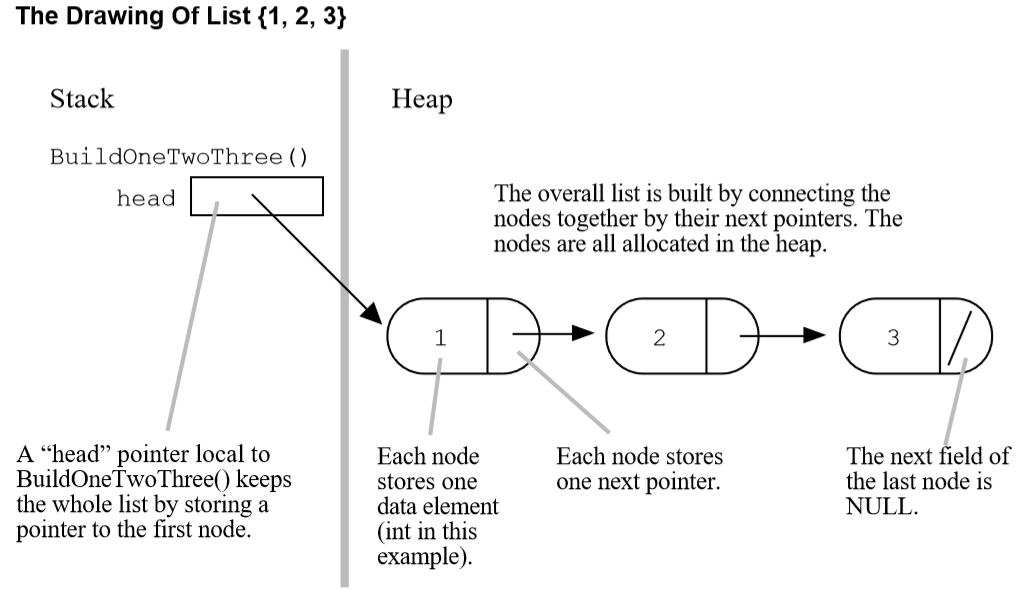
空链表的head的值是NULL,编程时要考虑到这种边界情况。
节点的定义:
1 | struct node { |
指向节点的指针类型是struct node*。
接着看看上图中的链表是怎么建立的?
1 | /* |
如何求链表中的元素个数呢?
1 | /* |
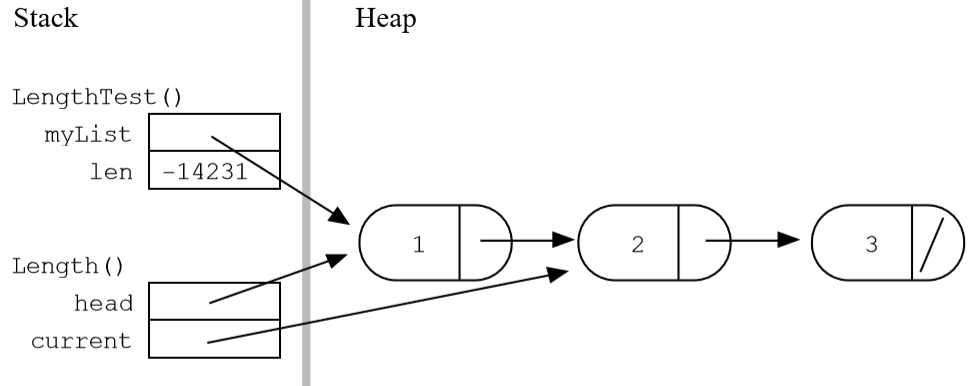
可以看到,传递进函数的只是头指针,这样调用者和被调用者都有了头指针,但是却共享了整个链表。
current指针占据的空间会被自动释放,但是堆中的链表仍然保留;while循环已经考虑了空链表的情况;current最后的值会是NULL。
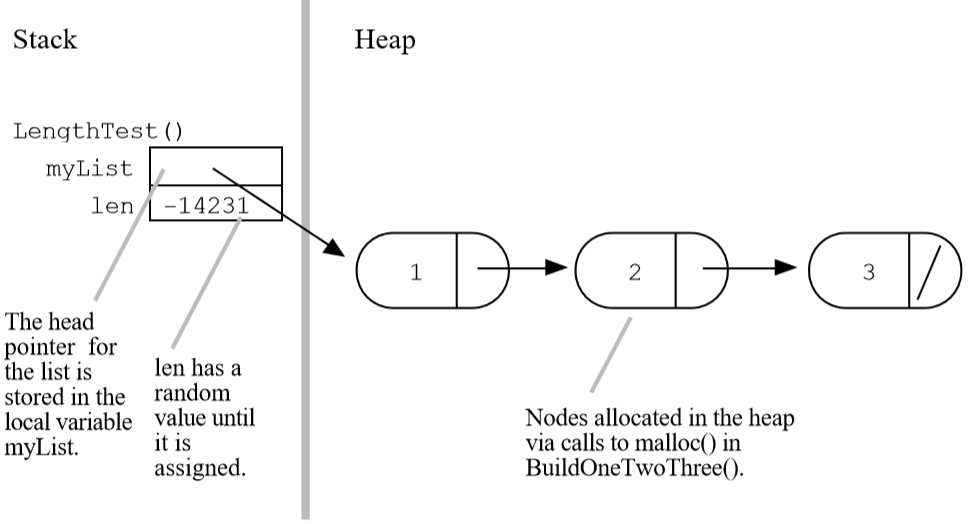
调用Length():
1 | void LengthTest() |
- 调用
Length()之前:
- 执行
Length()过程中:
链表建立
用BuildOneTwoThree()函数来建立链表未免有些古板,下面用头插法建立链表:
1、分配节点:
1 | struct node* newNode; |
2、让新节点的next指向当前链表的第一个节点:
1 | newNode->next = head; |
3、让head指针指向链表的第一个节点: 1
head = newNode;
1 | void LinkTest() |
如图: 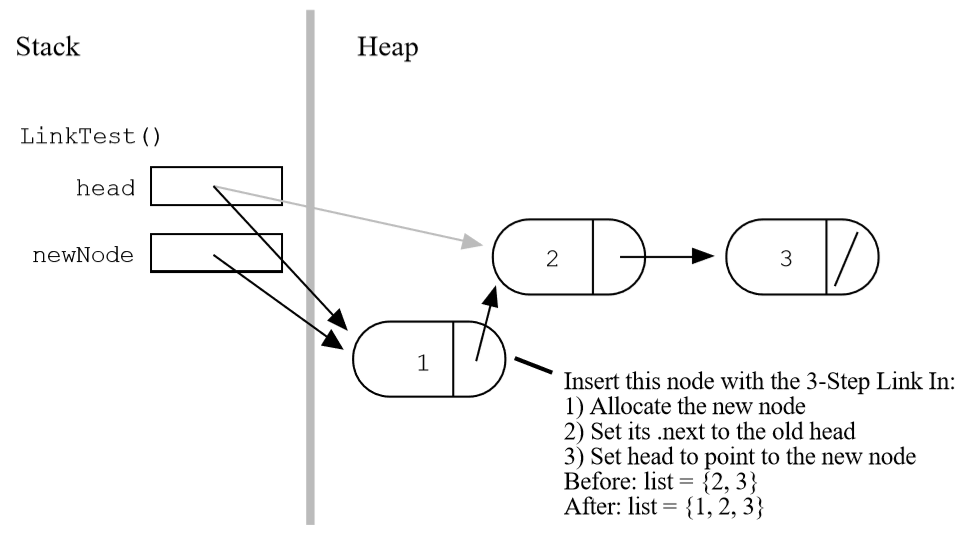
先看一个错误的示范: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void WrongPush(struct node* head,int data)
{
struct node* newNode = (struct node*)malloc(sizeof(struct node));
newNode->data = data;
newNode->next = head;
head = newNode; //NO this line does not work
}
void WrongPushTest()
{
struct node* head = buildTwoThree();
WrongPush(head, 1); //try to push 1 on front -- doesn't work
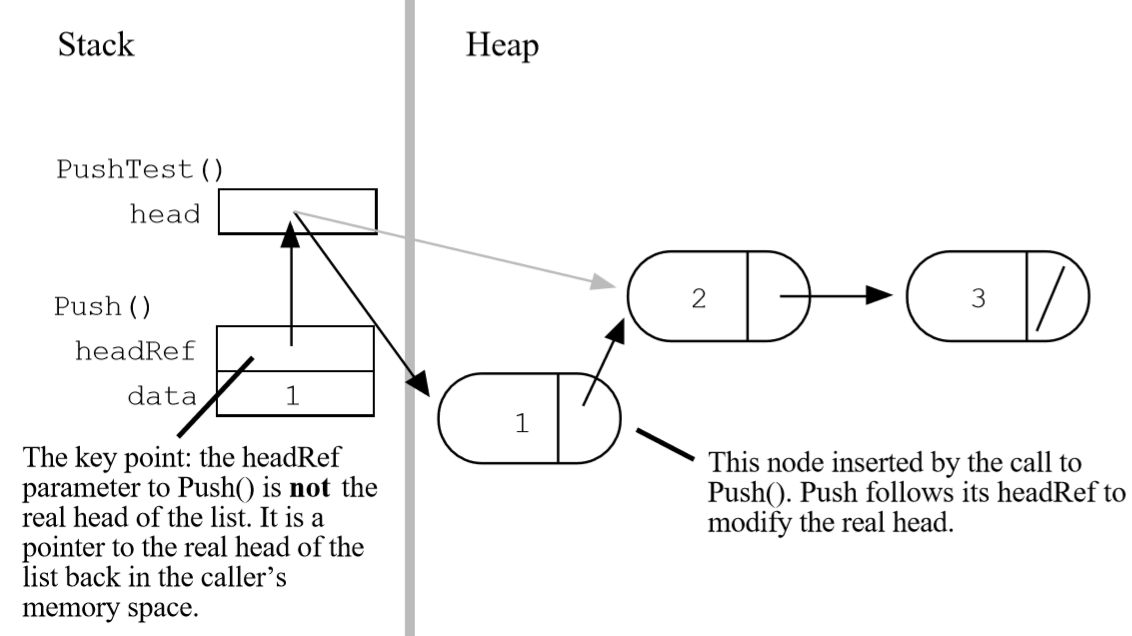
}WrongPush()中对head指针的改变不会影响到WrongPushTest中的我们需要的head指针。
这个问题传统的解决方案是传递当前值的指针给函数而不是传递一份当前值的拷贝,即:
要改变调用者中int的值,就传一个int*给被调用者。在这个例子中,要改变struct node*,就要传递struct node**。也即:head的类型是pointer to a struct node,想要改变这个指针,就需要传一个指向该指针的指针pointer to a pointer to a struct node。
规则就是:to modify caller memory, pass a pointer to that memory.
所以正确的代码如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/*
Takes a list and a data value.
Creates a new link with the given data and pushes it
onto the front of the list.
The list is not passed in by its head pointer.
Instead the list is passed in as a "reference" pointer
to the head pointer -- this allows us to modify the caller's memory.
*/
void Push(struct node** headRef,int data)
{
struct node* newNode = (struct node*)malloc(sizeof(struct node));
newNode->data = data;
newNode->next = *headRef; //the * to dereferences back to the real head
*headRef = newNode; //ditto
}
void PushTest()
{
struct node* head = buildTwoThree(); //suppose this returns the list {2,3}
Push(&head, 1); //note the &
Push(&head, 13);
//head is now the list {13,1,2,3}
}
如果是C++,那么可以用引用完成上述工作。
1 | /* |

