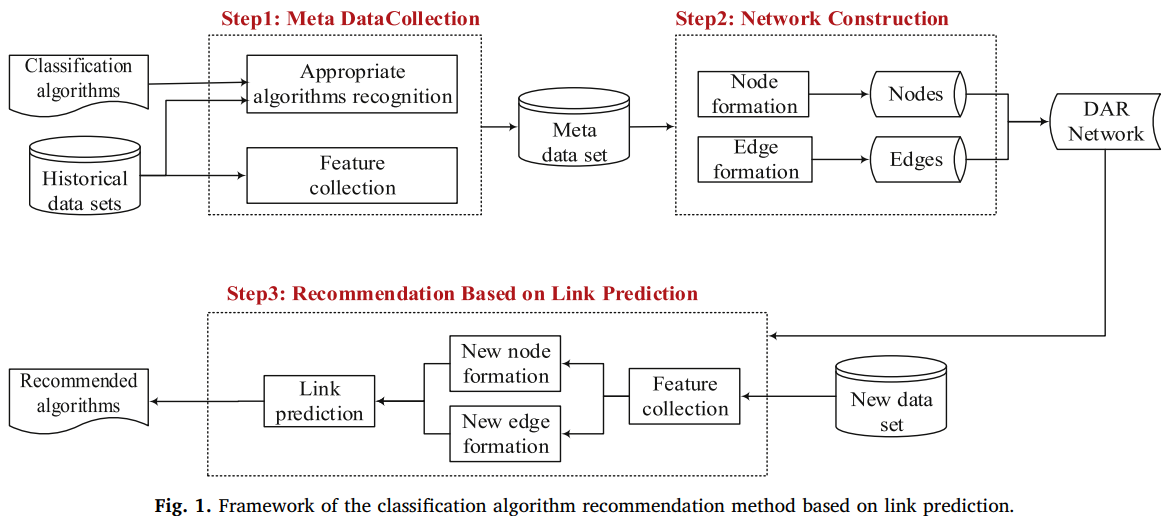
这篇文章主要还是在元模型上创新,采用基于链接预测的方式为新数据集推荐分类算法。基本框架如下:
用元学习做AutoML主要关注:元特征、元目标的表现形式、元模型。 ## 元特征
第一步包括提特征和识别可用算法。
目前流行的元特征有5种:
- statistical and information-theory based
- model structure based
- landmarking
- problem-complexity
- structural information
由于每个数据集可能有不定数目的可用算法,文章采用了multiple comparison
procedure:如果我们用acc作为衡量标准(除此以外本文还用了ARR作为标准,将时间因素也考虑进去),这个程序能用统计检验的方法发现一系列与最佳算法相差不显著的候选算法。文中具体使用的统计检验方法是Friedman
Test+Holm procedure test,即如果Friedman
Test认为所有算法性能相差不显著,那么所有的算法都是meta
target;否则以表现最佳的算法为参考,用Holm procedure
test去识别和最佳算法没有显著差异的算法们作为meta target。
这样就得到了元数据\(M=\{m_1,...,m_n\},m_i=<x_i,y_i>\),其中\(x_i=(f_{i1},...,f_{ip})\)是该数据集的p个元特征,\(y_i=(a_1,...,a_q)\)是q个合适的算法。
元目标形式
有4种:
- 单标签
- 多标签
- 连续值:预测算法的表现,回归问题
- 排序:预测算法之间的相对顺序
元模型
- 分类
- 回归
- ranking
本文将问题看作多标签分类,并采用DAR图+链接预测作为分类模型。
建的是一个异构图,有数据集(元特征作为结点属性)和算法(算法名作为属性)两种结点,有d-d和d-a两种无向边,d-d边的构建通过数据集间的相似性(欧氏距离最近的k个邻居,需要将元特征标准化min-max
scaling),d-a边就用每个数据集的候选算法构建。
建图的伪代码:

建好图后就可以推荐了,伪代码如下:

文章里LPMethod有3种:Katz,LRW,SRW。
综上,预测时需要的参数有:训练集\(D=\{d_1,...,d_n\}\),候选算法集\(A=\{a_1,..,a_m\}\),推荐的算法数目,每个数据集结点的邻边数目\(k\)。
评估
评估指标包括5个:Hamming损失、F值、acc、HitRatio、RA(推荐准确率)。
考虑DAR图的边的权重,类似概率图模型

