k-NN可以做分类及回归,对新的测试实例t,在训练集中找与t最近的k个实例,用投票法决定t属于哪个类,显然这是一种懒惰学习。
既然要找最近的k个,就会涉及距离度量问题,下面以2个样本点(每个点有n个维度)间的距离为例枚举一些度量方式:
- Minkowski距离:\(\sqrt[p]{\sum_{i=1}^{n}|x_{1i}-x_{2i}|^p}\),p=1时是曼哈顿距离,p=2时是欧氏距离,\(p\to\infty\)时是切比雪夫距离\(max_{i}|x_{1i}-x_{2i}|\)
- 标准欧式距离:为了克服欧氏距离各个维度数据粒度不一致对最终结果的影响,将每个维度标准化后采用欧氏距离的计算方法:\(y_{1i}=\cfrac{x_{1i}-u_i}{s_i}\),\(\sqrt{\sum_{i=1}^{n}(y_{1i}-y_{2i})^2}=\sqrt{\sum_{i=1}^{n}\cfrac{(x_{1i}-x_{2i})^2}{s_i^2}}\)
- Mahalanobis Distance:修正了各维度之间的相关性及粒度不一致性
样本向量\(x\)到均值向量\(u\)之间的马氏距离:
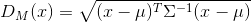
样本向量\(x\)到样本向量\(y\)之间的马氏距离:
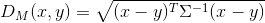
如果协方差矩阵是单位阵,即每个维度之间没有相关关系,即欧氏距离;如果协方差矩阵是对角阵,即标准欧氏距离 - Bhattacharyya Distance:衡量概率分布的相似性, \(D_B(p,q)=-ln(BC(p,q)),BC(p,q)=\sum\sqrt{p(x)q(x)},BC(p,q)=\int\sqrt{p(x)q(x)}dx\)
- 余弦相似性
- Jaccard Similarity Coefficient:衡量集合相似性:\(J(A,B)=\cfrac{|A\cap B|}{|A\cup B|}\)
Jaccard Distance:集合区分度:\(1-J(A,B)\)
假设有4个二值维度,样例A={0111},B={1011},则\(J=\frac{M_{11}}{M_{01}+M_{10}+M_{11}},J^{'}=1-J\),\(M_{11}\)表示A和B中均为1的维度个数 - Pearson Correlation Coefficient:
总体Pearson系数:\(\rho=\frac{Cov(X,Y)}{\sqrt{DXDY}}\)
相关距离:\(1-\rho\)
样本Pearson系数:\(r=\frac{\sum(X_i-\bar X)(Y_i-\bar Y)}{\sqrt{\sum(X_i-\bar X)^2\sum(Y_i-\bar Y)^2}}=\frac{1}{n-1}\sum(\frac{X_i-\bar X}{S_x})(\frac{Y_i-\bar Y}{S_y})\)
除了距离度量,还有k的选择:k太小容易过拟合,k太大会使得与测试实例较远的训练样例也会起作用。
kNN的实现:
1 | class NearestNeighbor: |
为了加快预测速度,可以使用k-d
tree来存储训练集,本质上也是一种平衡二叉树:
建树的过程可以递归进行:
- 确定划分域:对训练集,统计每个维度的方差,选择方差最大的属性,意味着沿着该维度数据比较分散,容易获得较高的分辨率
- 确定结点:将数据集按照划分域排序,正中间的点选为结点
- 确定左(值小于父亲)右(值大于父亲)孩子
- 设置左右孩子的parent域
往往训练样例的维度是很高的,所以很难每个维度都去分割,所以sklearn中的kNN如果用k-d
tree实现,会有一个参数leaf_size控制树的深度。
建好后,就可以快速查找测试样例的邻居。
假设训练集为\(X_{m\times k}\),测试集为\(Y_{n\times k}\),此时需要计算训练集中每条样本与测试集中每条样本的距离,为了加速矩阵运算,不能使用循环,最终结果为\(R_{m\times n}=X\circ X+Y\circ Y-2XY^T\),具体推导可以参考NumPy之计算两个矩阵的成对平方欧氏距离。

