马上就要成为社畜啦,把之前没有学完的课重新捡起来。DB一直是个心结,两年前尝试学了CMU的课,后来没能坚持下去,现在特来填坑!
由于之前的Gradescope不再维护,因此可能会遇到亿些问题,折腾了亿下感觉很麻烦,就做2022年了。。
Homework 1
hw1是SQL练习题,
C++ Primer
这个lab主要用来搭环境,熟悉C++ 17的一些Feature。
环境:WSL2,Ubuntu 18.04/20.04,终端科学上网
实现一个并发的字典树,有点tricky的是删除key时需要自底向上地递归,还需要学习下智能指针、std::move以及std::forward等特性。
BUFFER POOL MANAGER
整体要为Bustub做一个面向磁盘的存储管理系统:

第一次作业是要实现一个内存缓冲池:负责将物理页面在磁盘和主存之间移动,这样DBMS就可以支持比内存更大的数据库。缓冲池的操作对其它系统部件是透明的,比如系统通过唯一的页面标识符page_id_t向缓冲池要求访问页面,而不管页面是在内存中还是在磁盘上。
缓冲池的实现必须是线程安全的,多个线程同时访问时需要用latches保护(OS中叫locks)。
关于DBMS中的🔒:
- locks:高层次的逻辑原语,在事务的整个执行过程中保护数据库的内容(元组/表/数据库),可以rollback
- latches:低层次的保护原语,DBMS用来保护内部数据结构的安全访问(hash table, regions of memory),只在某个具体操作时使用,不可以rollback
具体来说:有2部分:LRU替换策略+缓冲池管理
- LRU
LRU的实现有多种方式:
1、数组+时间戳:每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。
2、双向链表:每次新插入数据的时候将新数据插到链表的头部;每次缓存命中(即数据被访问),则将数据移到链表头部;那么当链表满的时候,就将链表尾部的数据丢弃。
上面两种复杂度均是O(n)
3、双向链表+Hash Map:当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。本质上是list看作时间戳,hash table记录元素值到链表位置的映射关系,get和put均是O(1)。 - 缓冲池管理
缓冲池的组织形式是frame数目固定的数组,访问时将page从磁盘拷贝到frame。
与OS内存管理相似,也需要有page table记录哪些page在buffer pool中,page id -> frame id;page directory记录了磁盘上的位置,page id -> page locations in disk。
还需要有dirty位以及pin/ref counter记录当前正在访问的线程数目,只有flush或者置换脏页时才写回磁盘。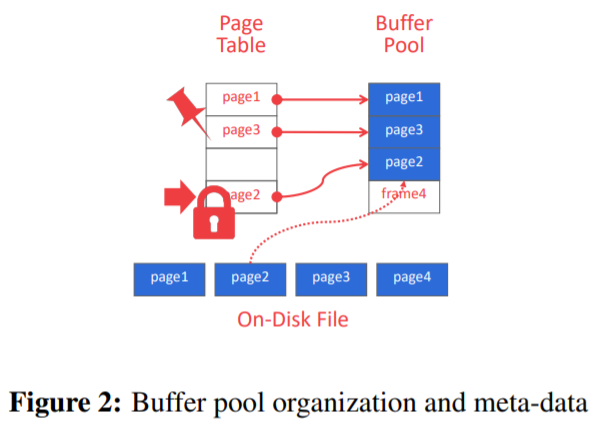 缓冲池和
缓冲池和Replacer的大小是相同的,如果page的ref counter变为0时就可以加入到Replacer中作为替补牺牲页面。
从缓冲池中根据ID fetch的时候有3种情况:
- 如果page在缓冲池,直接返回;
- 如果不在,但缓冲池有空闲frame,从磁盘读取page放入该frame;
- 如果不在且缓冲池没有空闲frame,从buffer中牺牲一页,从磁盘读取page放入对应的frame。
第一次提交忘了处理并发问题,只得了65分: 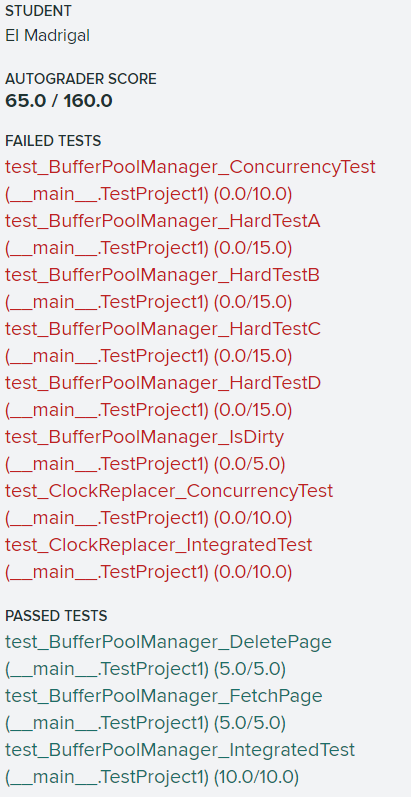
加了一些🔒后,还有2个test挂了:

isdirty一直过不去,后来在群里看到:只有page当前的脏位是false且传入is_dirty==true时才需要修改当前的脏位。这里我是这么理解的:如果页面应该标记为dirty那么传入的参数就是true:
- 当前为true &&
is_dirty==true:页面修改过,也做了正确标记,不用管; - 当前为false &&
is_dirty==true:页面其实修改过,但没有标记,改正; - 当前为false &&
is_dirty==false:页面没修改,标记正确,不用管; - 当前为true &&
is_dirty==false:页面没修改,标记为修改过,这种也不用管,大不了置换时写回磁盘耗费些时间。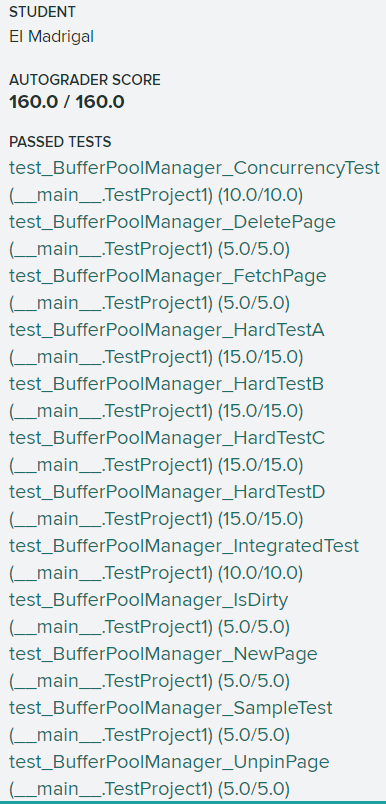
数据库真的太难了,尤其是涉及到并发控制的部分,我真的没有足够时间去debug这些,以后有空再继续做吧。。

