一、The Problem of Overfitting
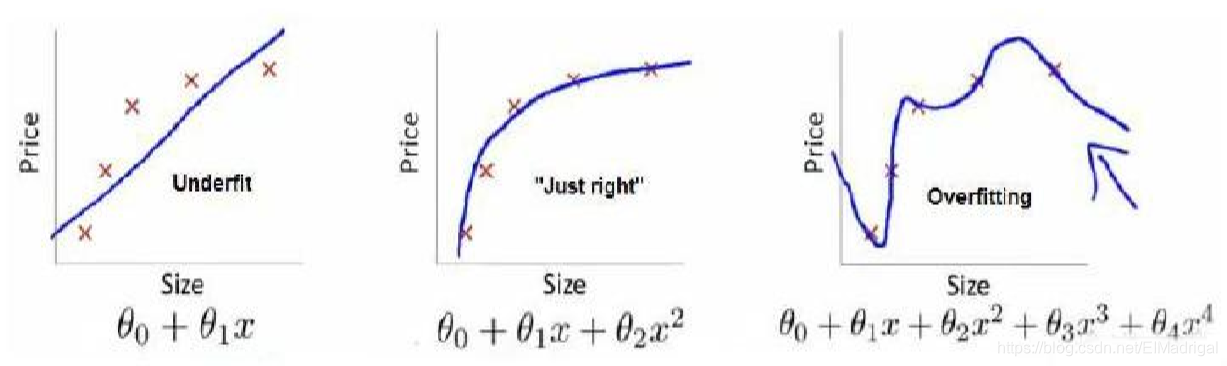
欠拟合(high bias):模型不能很好地适应训练集;
过拟合(high
variance):模型过于强调拟合原始数据,测试时效果会比较差。
处理过拟合:
1、丢弃一些特征,包括人工丢弃和算法选择;
2、正则化:保留所有特征,但减小参数的值。
二、Cost Function
过拟合一般是由高次项引起,那么我们可以通过增加某些项的cost,来降低它们的权重。
在梯度下降过程中,要使损失函数变小,那么\(\theta\)就会变得很小,所以假设函数中的\(\theta\)就会变小,该项的权重就会降低。
如果不知道要惩罚哪些特征,可以一起惩罚(除了\(\theta_0\))。
将代价函数改为:
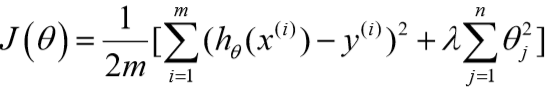
\(\lambda\)是正则化参数。
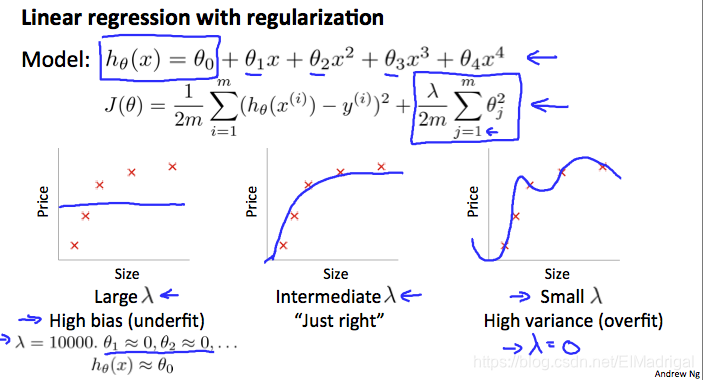
如果\(\lambda\)过大,那么所有的参数都会最小化,那么假设就会变为\(h_\theta(x)=\theta_0\),造成欠拟合。
三、Regularized Linear Regression
\(\theta_0\)没有正则化处理,所以梯度下降要分情况:
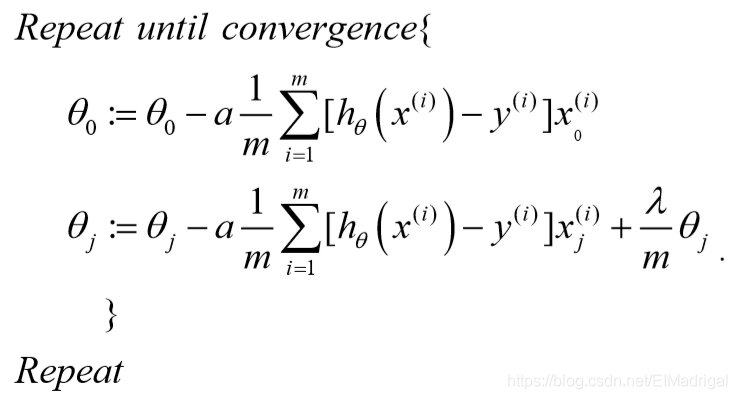
化简下:
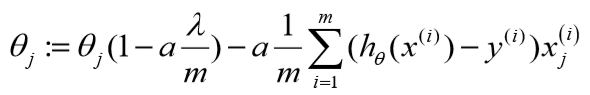
可以看到:
正则化后的参数更新比原来多减小了一个值。
再看线性回归的另外一个工具:常规方程。
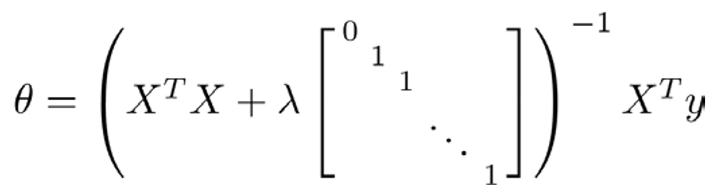
推导过程省略......
四、Regularized Logistic Regression
对于逻辑回归的代价函数,同样增加一个正则化表达式:
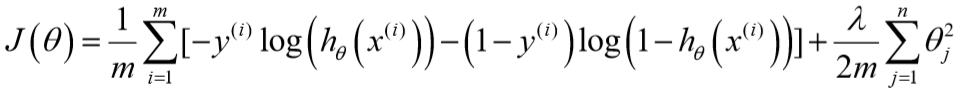
梯度下降算法与线性回归相同,不过\(h_\theta(x)\)不同。
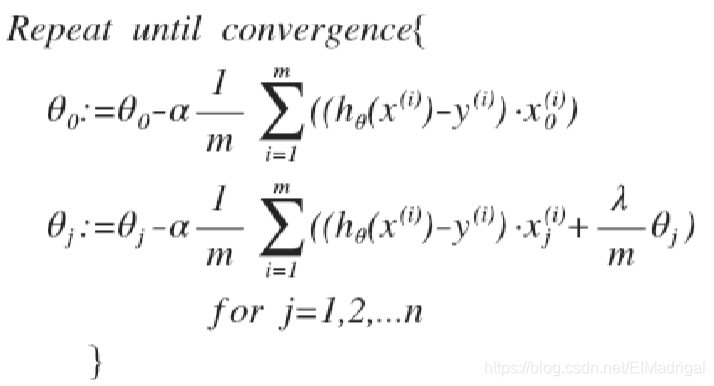
一、Evaluating a Learning Algorithm
训练后测试时如果发现模型表现很差,可以有很多种方法去更改:
- 用更多的训练样本;
- 减少/增加特征数目;
- 尝试多项式特征;
- 增大/减小正则化参数\(\lambda\)。
那么该怎么去选择采用哪种方式呢?
一般将70%的数据作为训练集,30%的数据作为测试集。
先用训练集最小化\(J_{train}(\Theta)\),得到一组参数值\(\Theta\);
然后计算测试集误差\(J_{test}(\Theta)\):
对于线性回归:

对于逻辑回归:
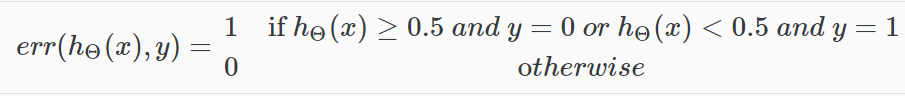
测试集的平均误差(分类错误的比率):
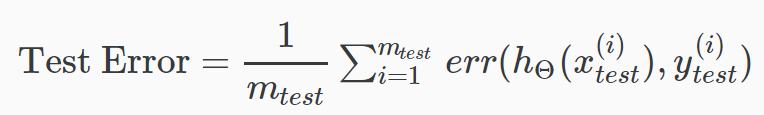
假设要选择用几次多项式\(d\)去作为假设函数,那么做法就是不断尝试\(d\),选择一个在测试集上损失最小的\(d\),以此作为模型泛化能力的衡量。但是这样是有问题的,因为\(d\)相当于是被测试集训练的,再用测试集去测试,很不公平。所以一般将数据集分为3部分:60%训练集、20%交叉验证集、20%测试集:

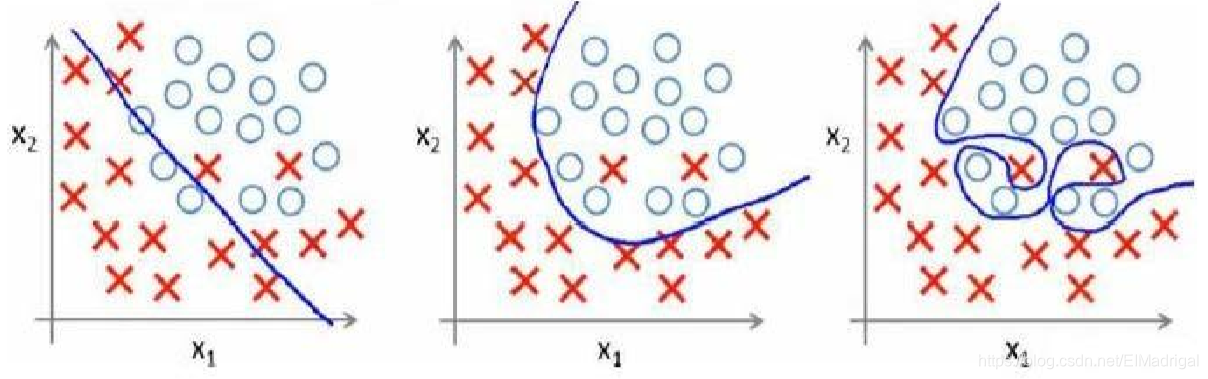
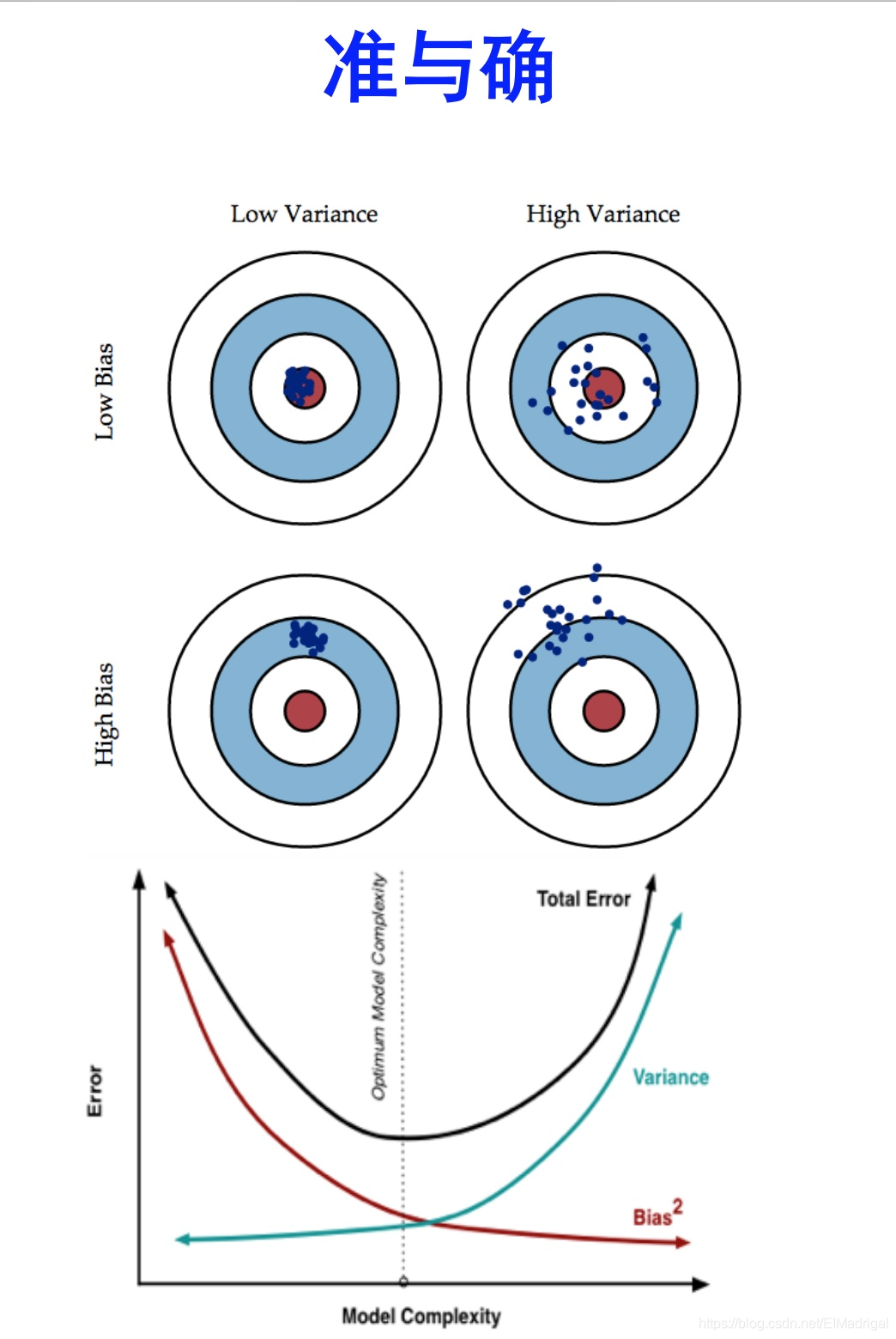
二、Bias vs. Variance
看图:
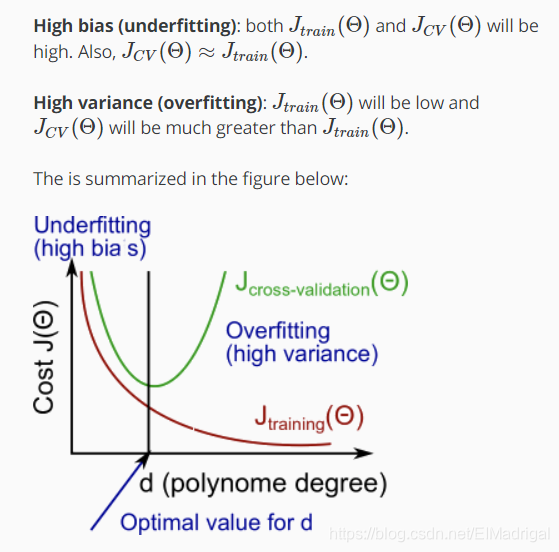
正则化和Bias/Variance的关系:
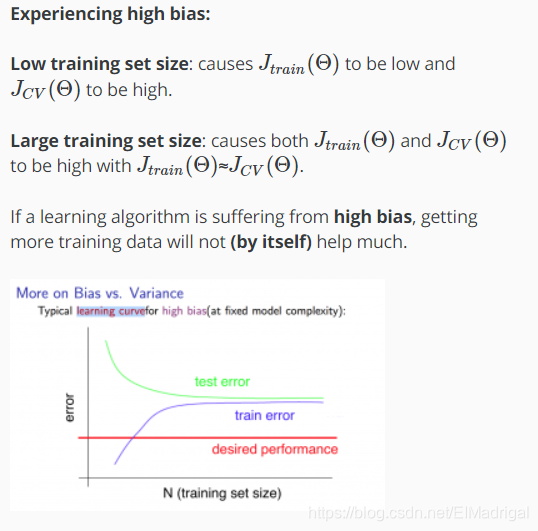
训练集大小与Bias/Variance的关系:
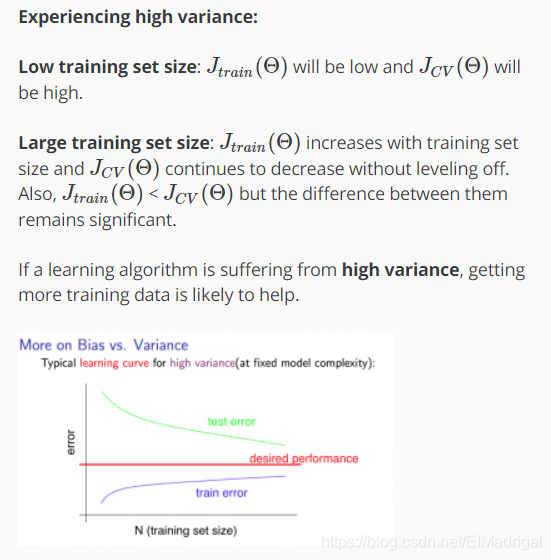
## 三、Error Analysis Andrew推荐的流程:

## 四、Handling Skewed Data
如果数据集中正负类的数据规模差距过大,只用误差衡量模型是不可靠的,此时需要查准率和召回率两个指标。

如何权衡这两个指标,一般使用\(F1\)得分: \[F_1=2\frac{PR}{P+R}\]

